- Machine Learning›
- お客様
Disney は深層学習を利用して、コンテンツの世界を分類
テレビシリーズ「Disneyland」の 1957 年のエピソードで、Walt Disney は、視聴者に自身の Burbank アニメーションスタジオを詳しく紹介しました。彼は、地下ライブラリに触れて、「当社の資料室の棚、テーブル、およびファイルキャビネットには、映画スタジオとしての当社のすべての歴史が詰められています」と述べています。
テレビシリーズ「Disneyland」の 1957 年のエピソードで、Walt Disney は、視聴者に自身の Burbank アニメーションスタジオを詳しく紹介しました。彼は、地下ライブラリに触れて、「当社の資料室の棚、テーブル、およびファイルキャビネットには、映画スタジオとしての当社のすべての歴史が詰められています」と述べています。
他のアニメーションスタジオがそうするかなり前に、Disney は、作家やイラストレーターが、参照やインスピレーションを受けられるようにするために、必要に応じてアーカイブにアクセスできるようにするべきだと主張しました。人気のダンボやピーターパンなどの絵やコンセプトアートワークなどが、この書庫に丁寧に収納されていました。そしてそれ以来、Disney はそれをそのまま保つことに取り組んできました。
ほぼ 1 世紀分のコンテンツが手元にあり、それがデジタル化される割合が高まってきているため、Disney はライブラリをこれまで以上に丁寧に整理する必要があります。(仮想) スタック間で秩序と清潔さを保つようにしているのは、Disney の Direct-to-Consumer & International (DTCI) テクノロジーチーム内の R&D エンジニアとインフォメーションサイエンティストの小さなチームです。DTCI は 2018 年に立ち上げられました。その目的の一部は、Walt Disney Company 全体の技術者と専門知識を結集し、テクノロジーを調整して、Disney の膨大な数のユニークなコンテンツとビジネスニーズをサポートすることでした。
組織システムの基盤はメタデータです。メタデータは、Disney の番組や映画のストーリー、シーン、キャラクターに関する情報です。例えば、バンビには、ウサギのサンパーやファリーヌ (バンビの子鹿の友達) などのキャラクターだけでなく、動物の種類、動物間の関係、各動物が描くキャラクターの原型を識別するメタデータタグがあります。自然の風景のようなもの (描かれている特定の種類の花に至るまで) の音楽、感情、ストーリーのトーンにも特定のタグがあります。その結果、このコンテンツすべてに適切なメタデータを適切にタグ付けして、適切に並べ替えることができるようにすることは、特に Disney の成長のペースを考えると、困難です。
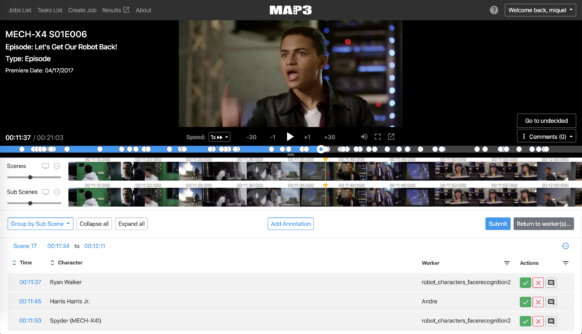
「テレビ番組、サッカー選手のチーム変更、スーパーヒーロー向けの新しい武器、新しい番組に新しいキャラクターが登場しました」と、チームのテクニカルリーダーである Miquel Farré 氏は述べています。これらすべてに、膨大な量の新鮮なメタデータが必要です。
Farré 氏と彼のチームは、AWS のサービスの助けを借りて、機械学習ツールと深層学習ツールを構築しています。これにより、このコンテンツに説明的なメタデータを自動的にタグ付けしてアーカイブプロセスをより効率的にしています。その結果、作家やアニメーターは、ミッキーマウスからモダン・ファミリーのフィル・ダンフィーまで、誰もがすばやく検索して詳しくなることができます。
メタデータの何がそれほど魔法がかっているのでしょうか?
ディズニーの画像提供
この作品を率いるチームは、もともと Disney & ABC Television Group の一翼として 2012 年に結成されました。何年にもわたって成長し、現在は Disney の DTCI テクノロジーグループの一部として、Disney の世界のスタイルと慣習の物差しと知識ベースになっています (例えば、バンビの動物の話の中で。白雪姫では、そうはなっていません)。チームは、クリエイティブコンテンツを正確に説明するメタデータを生成するための機械学習ツールについて、各ショーをユニークにするスタイルの特徴の説明に作家やアニメーターの力に頼っています。
このような創造的なチームメンバーは、作家やアニメーターから協力してもらうことでメリットを得ています。コンテンツが正確なメタデータでタグ付けされると、検索インターフェイスを介して必要なものをすばやく見つけることができます。例えば、グレイズ・アナトミーの作家は、不必要に繰り返すことを避けるために、あるエピソードでホイップル手術が何回取り上げられたかを知る必要があるかもしれません。一方、新しい漫画で海の底の水中生活を描くアーティストは、インスピレーションを得るために、リトル・マーメイドやファインディング・ニモで特定のキャラクターのポーズや位置を探したいと思うかもしれません。
しかし、すべてに適切なメタデータをタグ付けすると、すぐに労力の問題が発生します。手動のタグ付けはプロセスの重要な部分ですが、DTCI テクノロジーチームにはすべてのフレームを手動で分類する時間がありません。そのため、Farré 氏のチームは機械学習、そして最近では深層学習をメタデータの生成タスクに投入しました。目標は、Disney のナレッジベースの他の部分と一貫性のある方法で、あるシーンのコンポーネントに自動的にタグを付けることができる深層学習アルゴリズムを構築することです。人間はまだアルゴリズムのタグを承認する必要がありますが、このプロジェクトは、Disney ライブラリの整理にかかる作業を大幅に削減し、その中の検索の精度を向上させています。
さらに、この進歩により、エンジニアは AWS (アマゾン ウェブ サービス) を利用した深層学習モデルの開発により注力できるようになりました。その結果、さまざまな種類の Disney コンテンツ間でメタデータの作成を自動化するという彼らの取り組みが奏功しています。

深層学習はアニメーションにアイデンティティを与える
ディズニーの画像提供
最も成功した深層学習/メタデータプロジェクトの 1 つは、アニメーションの認識によって提示される問題を解決することです。
実写映画やテレビ番組の機械では、キャラクターを周囲から分離するのは比較的簡単です。しかし、アニメーションは物事がより複雑になります。例えば、あるキャラクターが生身の人間とポスターの両方に登場するアニメーションシーンを考えてみましょう (キャラクターが犯罪者で、指名手配の貼り紙が町中に掲示されているとします)。「アルゴリズムの場合、これは非常に複雑です」と Farré 氏は言います。
昨年、Farré 氏のチームは、アニメ化されたキャラクターを静的な表現から区別し、ドッペルゲンガーの群れの中でそれらを識別し (多くのキャラクターがほとんど同じであるダックテイルズのように)、ファンキーな照明のシーンでそれらを認識することができる (不思議の国のアリスで、アリスがチェシャ猫と最初に会ったとき、現れるのは歯を見せた笑顔だけです) 深層学習方法を開発しました。何が何であるかを決定すると、アルゴリズムは適切なメタデータでシーンにタグを付けることができます。
しかし、このモデルの真の力は、アニメーションコンテンツのどの部分にも適用できることにあります。つまり、すべてのグーフィー、ヘラクレス、エルザの新しいモデルを作成するのではなく、チームは一般的なモデルを使用するだけで済みます。このモデルは、わずかな調整を加えるだけで、あらゆるショーや映画のどのキャラクターでも機能します。
去年までは、チームは従来の機械学習アルゴリズムを使用していました。これは、深層学習アプローチよりも必要なデータは少ないけれども、結果が制限され、柔軟性が低下していました。従来のアルゴリズムは少ないデータ入力でうまく機能します。しかし、指数関数的にデータが増加する場合は、深層学習が大きな違いを生む可能性があります。
Farré 氏によると、深層学習モデルは、既にトレーニングされたネットワークの恩恵を受け、特定のユースケースに合わせて微調整することができます。特定のアニメキャラクターのケースでは、Disney は何千もの画像を使用してニューラルネットワークを微調整し、「アニメキャラクター」の概念を確実に理解できるようにしました。 次に、特定のショーごとに、いくつかのエピソードの数百の画像を使用してニューラルネットワークを再調整し、特定のショー内で「アニメーションキャラクター」を検出して解釈する方法を学習します。
Disney が従来の機械学習から深層学習へ移行する際、特に実験に関して AWS は重要なパートナーになりました。Elastic Cloud Computing (EC2) インスタンスにより、チームはモデルの新しいバージョンをすばやくテストできます。(アニメーション認識プロジェクトでは、Disney は事前にトレーニングされたモデルとともに PyTorch フレームワークを使用しています)。 深層学習では多くの研究が行われているため、チームは常に新しい新しい方法を実験しています。
メタデータの調査が非常に成功したため、Disney 全体が風に乗っています。Farré 氏によると、彼のチームは最近 ESPN のパーソナライズチームと連携して、業界をリードするデジタルアプリケーションやウェブサイトに掲載されるすべての記事や動画に関する詳細なメタデータを提供しました。あなたが Los Angeles Dodgers、Steph Curry、Minnesota Vikings や Manchester United のファンであることを製品がわかっている場合は、各記事に関するメタデータが多いほど、好みに最も合ったコンテンツを確実に提供できます。さらに、機械学習アルゴリズムとそれが提供するメタデータは、より高度な AI を強化して、時間の経過とともに (データの関係と動作に基づいて) さらに暗黙的なパーソナライズを推進できるようになります。
Farré 氏が考えているように、特に、Disney の特徴的なコンテンツ、キャラクター、製品の膨大で増え続けるライブラリを考えると、メタデータの用途は無限大です。「当社に退屈の二文字はありません」と Farré 氏は言い切ります。