- Machine Learning›
- Clients
Grâce au Deep Learning, Disney fait le tri dans un univers de contenus
Dans un épisode de 1957 de la série télévisée Disneyland, Walt Disney entraîne les spectateurs dans les profondeurs de son studio d'animation de Burbank. « Dans notre morgue », raconte-t-il en faisant référence à la bibliothèque souterraine, « ces étagères, ces tables et ces classeurs contiennent toute notre histoire en tant que studio de cinéma ».
Dans un épisode de 1957 de la série télévisée Disneyland, Walt Disney entraîne les spectateurs dans les profondeurs de son studio d'animation de Burbank. « Dans notre morgue », raconte-t-il en faisant référence à la bibliothèque souterraine, « ces étagères, ces tables et ces classeurs contiennent toute notre histoire en tant que studio de cinéma ».
Bien avant les autres studios d'animation, Disney a insisté pour que ses archives soient accessibles aux écrivains et aux illustrateurs qui pourraient en avoir besoin à titre de référence ou d'inspiration. Des dessins, des illustrations conceptuelles et d'autres œuvres de favoris tels que Dumbo et Peter Pan ont été soigneusement rangés dans ce coffre. Et au cours des années qui ont suivi, Disney a maintenu son engagement en faveur de la préservation.
Avec près d'un siècle de contenu disponible, dont une part croissante est numérique, Disney doit organiser sa bibliothèque avec plus de soin que jamais. Une petite équipe d'ingénieurs R&D et de scientifiques de l'information au sein de l'équipe technologique Direct-to-Consumer & International (DTCI) de Disney veille à l'ordre et à la propreté des piles (virtuelles). La DTCI a été créée en 2018, en partie pour rassembler des technologues et des experts de l'ensemble de The Walt Disney Company et aligner la technologie pour répondre à la vaste gamme de contenus uniques et de besoins commerciaux de Disney.
Le système organisationnel repose sur les métadonnées : des informations sur les histoires, les scènes et les personnages des émissions et des films Disney. Par exemple, Bambi aurait des balises de métadonnées qui identifient non seulement des personnages tels que Thumper le lapin ou Faline (l'ami fauve de Bambi), mais aussi le type d'animal, les relations entre les animaux et les archétypes de personnages que chaque animal représente. Des éléments tels que les scènes de la nature, jusqu'aux types spécifiques de fleurs représentés, la musique, les sentiments et le ton de l'histoire, ont également des étiquettes spécifiques. Par conséquent, il est difficile de baliser correctement tout ce contenu avec les bonnes métadonnées qui permettent de le trier correctement, en particulier si l'on considère le rythme effréné de la croissance de Disney :
« Nous avons de nouveaux personnages dans des émissions de télévision, des joueurs de football qui changent d'équipe, de nouvelles armes pour les super-héros, de nouvelles émissions », explique Miquel Farré, le responsable technique de l'équipe, et tout cela nécessite un tas de nouvelles métadonnées.
Avec l'aide des services AWS, lui et son équipe développent des outils d'apprentissage automatique et d'apprentissage en profondeur pour baliser automatiquement ce contenu avec des métadonnées descriptives afin de rendre le processus d'archivage plus efficace. Ainsi, les scénaristes et les animateurs peuvent rapidement rechercher et se familiariser avec tout le monde, de Mickey Mouse à Phil Dunphy de Modern Family.
Qu'y a-t-il de si magique dans les métadonnées ?
Image publiée avec l'aimable autorisation de Disney
L'équipe chargée de ce travail a été initialement formée en 2012, au sein du Disney & ABC Television Group. Au fil des ans, il s'est développé et, faisant désormais partie du groupe DTCI Technology de Disney, il est devenu l'indice et la base de connaissances sur les styles et les conventions de l'univers Disney (par exemple, dans Bambithe animals talk, dans Blanche-Neige, ils ne le font pas). Pour que ses outils d'apprentissage automatique génèrent des métadonnées décrivant avec précision le contenu créatif, l'équipe compte sur les rédacteurs et les animateurs pour expliquer les caractéristiques stylistiques qui rendent chaque émission unique.
Ces membres de l'équipe créative bénéficient de leur coopération. Une fois que le contenu est étiqueté avec des métadonnées précises, ils peuvent rapidement trouver ce dont ils ont besoin grâce à une interface de recherche. Par exemple, un rédacteur de Grey's Anatomy, pour éviter toute redondance, pourrait avoir besoin de savoir combien de fois la chirurgie de Whipple a été présentée dans un épisode. Pendant ce temps, un artiste dessinant la vie sous-marine pour un nouveau dessin animé se déroulant sous la mer pourrait s'inspirer d'une pose ou d'un positionnement de personnage spécifique dans La Petite Sirène : Le Monde de Nemo.
Mais le fait de tout baliser avec les bonnes métadonnées pose rapidement un problème de main-d'œuvre : même si le balisage manuel constitue une partie importante du processus, l'équipe de DTCI Technology n'a pas le temps de catégoriser manuellement chaque image. C'est pourquoi l'équipe de Farré a fait appel à l'apprentissage automatique, et plus récemment à l'apprentissage profond, pour générer des métadonnées. L'objectif est de créer des algorithmes d'apprentissage en profondeur capables de baliser automatiquement les composants d'une scène d'une manière cohérente avec le reste de la base de connaissances Disney. Les humains doivent encore approuver les balises de l'algorithme, mais le projet réduit considérablement le travail nécessaire à l'organisation de la bibliothèque Disney, en améliorant la précision des recherches qu'elle contient.
De plus, ces progrès permettent aux ingénieurs de se concentrer davantage sur le développement de modèles d'apprentissage profond à l'aide d'AWS (Amazon Web Services). Par conséquent, leurs efforts pour automatiser la création de métadonnées pour différents types de contenus Disney portent leurs fruits.

L'apprentissage profond donne une identité aux animations
Image publiée avec l'aimable autorisation de Disney
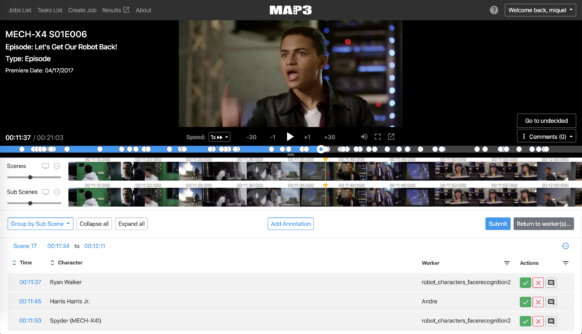
L'un des projets d'apprentissage profond et de métadonnées les plus réussis a été de résoudre les problèmes posés par la reconnaissance des animations.
Dans un film ou une émission de télévision en direct, pour une machine, séparer un personnage de son environnement est relativement simple. Mais l'animation complique les choses. Prenons l'exemple d'une scène animée dans laquelle un personnage apparaît à la fois en chair et en os et sur une affiche (disons que le personnage est un criminel et que des panneaux de recherche ont été affichés dans toute la ville). « Pour un algorithme, c'est extrêmement complexe », explique Farré.
L'année dernière, l'équipe de Farré a développé une méthode d'apprentissage profond qui permet de distinguer les personnages animés de leurs représentations statiques, de les identifier au sein d'une foule de sosies (comme dans DuckTales, où de nombreux personnages sont à peu près identiques) et de les reconnaître dans des scènes aux éclairages géniaux (dans Alice au pays des merveilles, quand Alice se rencontre pour la première fois dans le chat du Cheshire, il ne révèle que son sourire plein de dents). Après avoir décidé de quoi il s'agit, l'algorithme peut étiqueter les scènes avec les métadonnées appropriées.
Mais la véritable force du modèle réside dans le fait qu'il peut être appliqué à n'importe quel contenu animé. Autrement dit, plutôt que de créer un nouveau modèle pour chaque Dingo, Hercule et Elsa, l'équipe n'a qu'à utiliser son modèle générique qui, avec de légers ajustements, fonctionnera pour n'importe quel personnage de n'importe quelle émission ou film.
Avant cette année, l'équipe travaillait avec des algorithmes d'apprentissage automatique plus traditionnels, qui nécessitent moins de données qu'une approche d'apprentissage en profondeur, mais qui aboutissaient également à des résultats plus limités et moins flexibles. Avec moins d'entrées de données, les algorithmes traditionnels fonctionnent bien. Mais lorsque vous disposez d'une quantité exponentielle de données, le deep learning peut faire toute la différence.
Selon Farré, le modèle d'apprentissage profond peut désormais tirer parti de réseaux déjà formés et être adapté à des cas d'utilisation spécifiques. Dans le cas spécifique des personnages animés, Disney a peaufiné un réseau neuronal contenant des milliers d'images pour s'assurer qu'il comprend le concept de « personnage animé ». Ensuite, pour chaque émission spécifique, le réseau neuronal est réajusté à l'aide de quelques centaines d'images provenant de quelques épisodes afin d'apprendre comment les « personnages animés » doivent être détectés et interprétés dans l'émission spécifique.
AWS a joué un rôle clé dans la transition de Disney de l'apprentissage automatique traditionnel au deep learning, en particulier en matière d'expérimentation. Les instances EC2 d'Elastic Cloud Computing permettent à l'équipe de tester rapidement de nouvelles versions du modèle. (Pour le projet de reconnaissance d'animations, Disney utilise le framework PyTorch avec des modèles pré-entraînés.) Comme de nombreuses recherches sont en cours dans le domaine de l'apprentissage profond, l'équipe expérimente constamment de nouvelles méthodes.
La recherche sur les métadonnées a connu un tel succès que les départements de Disney en ont pris plein la vue. Farré a indiqué que son équipe s'était récemment engagée avec l'équipe de personnalisation d'ESPN pour fournir des métadonnées détaillées sur tous les articles et vidéos publiés sur les applications numériques et les sites Web de pointe du secteur. Si le produit sait que vous êtes fan des Los Angeles Dodgers, de Steph Curry, des Vikings du Minnesota et de Manchester United, plus il contient de métadonnées sur chaque article, plus il pourra vous proposer un contenu correspondant le mieux à vos préférences. En outre, les algorithmes d'apprentissage automatique et les métadonnées qu'ils fournissent peuvent alimenter une IA plus avancée afin de favoriser une personnalisation implicite accrue (basée sur les relations et le comportement des données) au fil du temps.
Selon Farré, les applications de métadonnées sont infinies, en particulier si l'on tient compte de la vaste bibliothèque croissante de contenus, de personnages et de produits distinctifs de Disney. « Je pense que nous n'allons pas nous ennuyer », a-t-il dit.
Témoignages connexes
Coinbase utilise le machine learning pour permettre d'échanger des cryptomonnaies de manière sécurisée
Capital One utilise le machine learning pour fournir à ses clients une protection optimale contre la fraude
 En savoir plus »
En savoir plus »
