- Machine Learning›
- Clientes
Con el aprendizaje profundo, Disney clasifica un universo de contenido
En un episodio de 1957 de la serie de televisión Disneyland, Walt Disney lleva a los espectadores a las profundidades de su estudio de animación de Burbank. «En nuestra morgue», dice, refiriéndose a la biblioteca subterránea, «estos estantes, mesas y archivadores contienen toda nuestra historia como estudio cinematográfico».
En un episodio de 1957 de la serie de televisión Disneyland, Walt Disney lleva a los espectadores a las profundidades de su estudio de animación de Burbank. «En nuestra morgue», dice, refiriéndose a la biblioteca subterránea, «estos estantes, mesas y archivadores contienen toda nuestra historia como estudio cinematográfico».
Mucho antes que otros estudios de animación, Disney insistió en que su archivo fuera accesible para escritores e ilustradores que pudieran necesitarlo como referencia o inspiración. En esta bóveda se guardaron cuidadosamente dibujos, obras de arte conceptual y más de favoritos como Dumbo y Peter Pan. Y en los años transcurridos desde entonces, Disney ha mantenido su compromiso con la preservación.
Con casi un siglo de contenido disponible, un porcentaje cada vez mayor de contenido digital, Disney debe organizar su biblioteca con más cuidado que nunca. Un pequeño equipo de ingenieros de I+D y científicos de la información del equipo de tecnología directa al consumidor e internacional (DTCI) de Disney se encarga de mantener el orden y la limpieza entre las estanterías (virtuales). DTCI se formó en 2018, en parte para reunir a tecnólogos y expertos de toda The Walt Disney Company y alinear la tecnología para respaldar la enorme variedad de contenido único y necesidades comerciales de Disney.
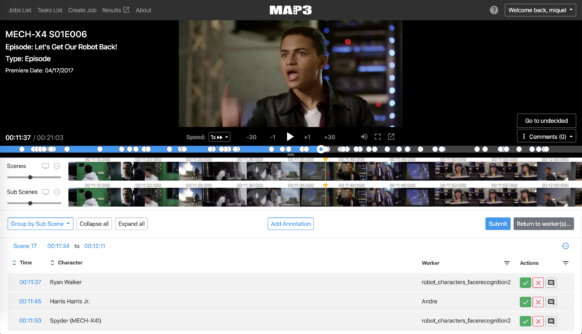
La base del sistema organizativo son los metadatos: información sobre las historias, escenas y personajes de las series y películas de Disney. Por ejemplo, Bambi tendría etiquetas de metadatos que identificaran no solo personajes como el conejo Thumper o Faline (el amigo cervatillo de Bambi), sino también el tipo de animal, las relaciones entre los animales y los arquetipos de personajes que representa cada animal. Cosas como las escenas de la naturaleza (hasta los tipos específicos de flores representadas), la música, el sentimiento y el tono de la historia, también tienen etiquetas específicas. Como resultado, etiquetar adecuadamente todo este contenido con los metadatos correctos que permitan clasificarlo correctamente es un desafío, especialmente teniendo en cuenta el enorme ritmo de crecimiento de Disney:
«Tenemos nuevos personajes en las series de televisión, jugadores de fútbol que cambian de equipo, nuevas armas para los superhéroes, nuevas series», afirma Miquel Farré, director técnico del equipo, y todo esto requiere un montón de metadatos nuevos.
Con la ayuda de los servicios de AWS, él y su equipo están creando herramientas de aprendizaje automático y aprendizaje profundo para etiquetar automáticamente este contenido con metadatos descriptivos para que el proceso de archivado sea más eficiente. Como resultado, los escritores y animadores pueden buscar rápidamente a todo el mundo y familiarizarse con él, desde Mickey Mouse hasta Phil Dunphy de Modern Family.
¿Qué tienen de mágico los metadatos?
Imagen cortesía de Disney
El equipo que dirige este trabajo se formó originalmente en 2012, como parte del Disney & ABC Television Group. A lo largo de los años, ha crecido y, ahora, como parte del grupo de tecnología DTCI de Disney, se ha convertido en el índice y la base de conocimientos de los estilos y convenciones del universo Disney (por ejemplo, en Bambi, los animales hablan, en Blancanieves, no). Para que sus herramientas de aprendizaje automático generen metadatos que describan con precisión el contenido creativo, el equipo depende de los guionistas y animadores para explicar las características estilísticas que hacen que cada espectáculo sea único.
Estos miembros creativos del equipo se benefician de su cooperación. Una vez que el contenido está etiquetado con metadatos precisos, pueden encontrar rápidamente lo que necesitan a través de una interfaz de búsqueda. Por ejemplo, un escritor de Grey's Anatomy, para evitar redundancias, podría necesitar saber cuántas veces la cirugía de Whipple ha aparecido en un episodio. Mientras tanto, un artista que dibuje la vida submarina para una nueva caricatura que tenga lugar bajo el mar podría querer buscar una pose o posición específica de un personaje en La Sirenita o Buscando a Nemo para inspirarse.
Sin embargo, etiquetar todo con los metadatos correctos presenta rápidamente un problema de trabajo: aunque el etiquetado manual es una parte importante del proceso, el equipo de tecnología de DTCI no tiene tiempo para clasificar manualmente cada fotograma. Por eso, el equipo de Farré ha dedicado el aprendizaje automático y, más recientemente, al aprendizaje profundo, a la tarea de generar metadatos. El objetivo es crear algoritmos de aprendizaje profundo que puedan etiquetar automáticamente los componentes de una escena de forma coherente con el resto de la base de conocimientos de Disney. Los humanos aún necesitan aprobar las etiquetas del algoritmo, pero el proyecto está reduciendo significativamente el trabajo que implica organizar la biblioteca de Disney, mejorando la precisión de las búsquedas dentro de ella.
Además, este progreso permite a los ingenieros centrarse más en el desarrollo de modelos de aprendizaje profundo con AWS (Amazon Web Services). Como resultado, sus esfuerzos por automatizar la creación de metadatos en diferentes tipos de contenido de Disney van en aumento.

El aprendizaje profundo da identidad a las animaciones
Imagen cortesía de Disney
Uno de los proyectos de aprendizaje profundo y metadatos más exitosos ha sido resolver los problemas que presenta el reconocimiento de animaciones.
En una película o programa de televisión de acción real, para una máquina, separar a un personaje de su entorno es relativamente sencillo. Pero la animación complica las cosas. Por ejemplo, tomemos una escena animada en la que un personaje aparece tanto en persona como en un póster (digamos que el personaje es un criminal y que hay carteles de «Se busca» por toda la ciudad). «Para un algoritmo, esto es extremadamente complejo», dijo Farré.
El año pasado, el equipo de Farré desarrolló un método de aprendizaje profundo que permite distinguir a los personajes animados de sus representaciones estáticas, identificarlos entre una multitud de dobles (como en DuckTales, donde muchos personajes son prácticamente idénticos) y reconocerlos en escenas con una iluminación divertida (en Alicia en el país de las maravillas, cuando Alicia se encuentra por primera vez en el gato de Cheshire, lo único que revela es su sonrisa dentada). Una vez decidido qué es qué, el algoritmo puede etiquetar las escenas con los metadatos apropiados.
Pero el verdadero poder del modelo es que se puede aplicar a cualquier pieza de contenido animado. Es decir, en lugar de crear un nuevo modelo para cada Goofy, Hércules y Elsa, el equipo solo necesita usar su modelo genérico, que, con pequeños ajustes, funcionará para cualquier personaje de cualquier serie o película.
Antes de este año, el equipo trabajaba con algoritmos de aprendizaje automático más tradicionales, que requieren menos datos que un enfoque de aprendizaje profundo, pero que también generaban resultados más limitados y menos flexibles. Con menos entradas de datos, los algoritmos tradicionales funcionan bien. Pero cuando tienes más datos de forma exponencial es cuando el aprendizaje profundo puede marcar una gran diferencia.
Ahora, afirma Farré, el modelo de aprendizaje profundo puede beneficiarse de redes ya capacitadas y adaptarse a casos de uso específicos. En el caso específico de los personajes animados, Disney ajustó una red neuronal con miles de imágenes para asegurarse de que entiende el concepto de «personaje animado». Luego, para cada programa específico, la red neuronal se reajusta utilizando solo unos cientos de imágenes de unos pocos episodios para aprender cómo se deben detectar e interpretar los «personajes animados» dentro del programa específico.
AWS ha sido un socio clave en la transición de Disney del aprendizaje automático tradicional al aprendizaje profundo, especialmente en lo que respecta a la experimentación. Las instancias EC2 de computación en nube elástica permiten al equipo probar rápidamente nuevas versiones del modelo. (Para el proyecto de reconocimiento de animaciones, Disney utiliza el marco PyTorch con modelos previamente entrenados). Dado que se están realizando muchas investigaciones sobre el aprendizaje profundo, el equipo experimenta constantemente con métodos nuevos y novedosos.
La investigación de metadatos ha tenido tanto éxito que los departamentos de Disney se han enterado. Farré dijo que su equipo colaboró recientemente con el equipo de personalización de ESPN para proporcionar metadatos detallados sobre todos los artículos y vídeos que aparecen en las aplicaciones digitales y sitios web líderes del sector. Si el producto sabe que eres fanático de los Dodgers de Los Ángeles, Steph Curry, los Minnesota Vikings y el Manchester United, cuantos más metadatos tenga sobre cada artículo, se asegurará de que recibas el contenido que mejor se adapte a tus preferencias. Además, los algoritmos de aprendizaje automático y los metadatos que ofrecen pueden impulsar una IA más avanzada para impulsar una mayor personalización implícita (basada en las relaciones y el comportamiento de los datos) a lo largo del tiempo.
En opinión de Farré, las solicitudes de metadatos son infinitas, especialmente teniendo en cuenta la vasta y creciente biblioteca de contenido, personajes y productos distintivos de Disney. «Creo que no nos aburriremos», dijo.
Historias relacionadas
Coinbase usa el aprendizaje automático para generar un intercambio seguro de criptomonedas
Capital One aprovecha el aprendizaje automático para evitar que sus clientes sean víctimas de fraudes
 Más información »
Más información »
